At the core of our project, there is always situation awareness (SA). Just in case the term is not familiar yet: SA describes how humans perceive the elements of a given environment within spatial and temporal confinements – and how that perception affects their performance and decision-making in the situation at hand. SA has become particularly important where decision-making happens under time pressure, remotely or among multiple operators, e.g. at a public authority managing natural disasters and sending out first responders – or at a media organization preparing for an outdoor TV production.
Perception, Comprehension, and Projection
Classic models – like the one that goes back to Mica Endsley – define three levels of SA:
- Perception
The first and most basic level of SA is about monitoring, spotting, and recognizing things. L1SA is achieved as agents become aware of different elements a situation
(e.g. other people and objects) and are also able to detect their status (condition, location etc.).
- Comprehension
The second level of SA is about recognizing, interpreting, and evaluating the lie of the land. L2SA is achieved when agents understand what is going on around them (at present) – and what that means for their objectives. - Projection
The third and highest level is about projections and predictions. L3SA is achieved when agents extrapolate the information they have collected in L1SA and L2SA and are thus able to gain insights on what the situation (and elements therein) will probably look like in the future – and in what ways the mission may have to be adjusted.
Endsley’s model has been criticized, revised and extended since it was first published in 1995, but for the sake of simplicity – and because this is not an academic forum – we will not go into further details. Instead, we would rather like to briefly explain how the three levels of SA in XR4DRAMA are both similar to and different from the influential classic model outlined above.
Increasingly sophisticated renderings of locations
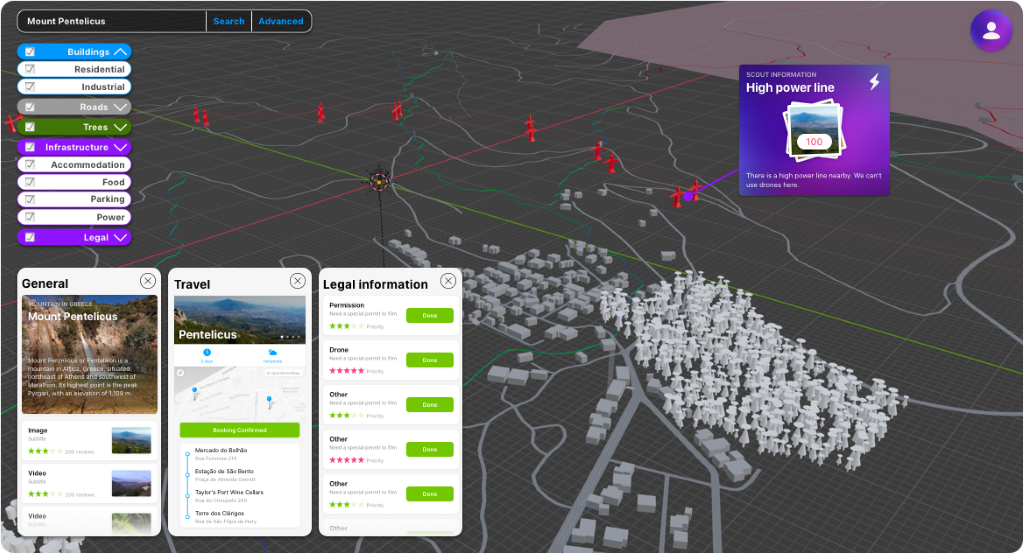
on a location (L2SA) – but no immersive mode (L3SA) yet.
XR4DRAMA wants to build a digital platform for people who are – remotely or directly – planning for and dealing with events and incidents in a specific location. Just like in the classic model, the XR4DRAMA SA levels will be subsequent ones that build on each other and go from low to high complexity. However, while Endsley et al. start out with simple perception and aim for sophisticated projections, the XR4DRAMA platform will rather focus on providing as much information as possible to achieve good enough or very good comprehension. That being said, the level of detail will always depend on the specific use case and the time that is available to users of the platform.
In any case, the consortium foresees a platform that makes use of three different levels:
- Simple Mode
XR4DRAMA L1SA will be a simple, yet appealing visualisation/representation of a location that includes first information on geography, sociographics etc. as well as a couple of images and/or videos. L1SA is created automatically and relies on data from a number of (publicly available) web services. - Enhanced Mode
XR4DRAMA L2SA will be an enhanced visualisation/representation that draws on recent, exclusive content and updated information stemming from people with gadgets and sensors who are operating in the field (first responders or location scouts). We will have the XR4DRAMA system process their data and combine it with what has already been collected and visualized for XR4DRAMA L1SA. - Immersive Mode
XR4DRAMA L3SA will be a complex and comprehensive representation of a specific location, close to a simulation of an event within that environment. Here, the platform aggregates all the information from L1SA and L2SA and also allows users to immerse themselves in the situation via VR or AR features and tools (with a possible extra focus on more sophisticated audio). Ideally, this representation also enables test runs of specific strategies and methods ( e.g. the simulation of camera movements in the media use case), thus connecting with the concept of projection/prediction in classic L3SA.
In general, the consortium envisions a solution where all levels and functions are accessible to all stakeholders in a scenario, albeit in graduations and on different devices (because nobody wants to wear a VR google in the field). As already mentioned on the project vision page, the ultimate dream is to create a platform that enables shared, distributed SA.
Photo by Cameron Venti on Unsplash